graph TD
A[Developer writes and commits code] --> B[Push code to GitHub]
B --> C[GitHub triggers Jenkins via Webhook]
C --> D[Clone repository to Jenkins workspace]
D --> E[Run CI Pipeline]
subgraph CI
E1[Build Code]
E2[Run Unit Tests]
E3[Static Code Analysis]
E4[Package Build Artifacts]
end
E --> E1 --> E2 --> E3 --> E4 --> F[Store Build Artifacts in Artifact Repository]
F --> G[Deploy to Staging Environment]
subgraph CD
G1[Run Smoke Tests]
G2[Deploy to Production]
G3[Run Acceptance Tests]
end
G --> G1 --> G2 --> G3 --> H[Notify Team of Deployment Status]
H --> I[Monitor Application Performance]
I --> J[Feedback to Development Team]
Shell commands table
| Category | Command | Sub-command | Description |
|---|---|---|---|
| File Operations and Text Processing | cat |
cat filename |
Displays the contents of filename. |
cat file1 file2 > combined_file |
Concatenates file1 and file2 into combined_file. |
||
grep |
grep "pattern" file |
Searches for "pattern" in file. |
|
grep -r "pattern" directory/ |
Recursively searches for "pattern" in directory and its subdirectories. |
||
grep -i "pattern" file |
Searches for "pattern" in file case-insensitively. |
||
sed |
sed 's/old/new/g' file |
Replaces all occurrences of "old" with "new" in file. |
|
sed -i '1d' file |
Deletes the first line of file in place. |
||
awk |
awk -F"\\t" '{print $8}' file |
Prints the 8th column of a tab-separated file. |
|
awk '{sum += $1} END {print sum}' file |
Sums the first column of file and prints the total. |
||
sort |
sort file |
Sorts the lines in file alphabetically. |
|
sort -t $'\\t' -k 2 file |
Sorts file based on the second tab-separated column. |
||
sort -t $'\\t' -rk 2 file |
Sorts file in reverse order based on the second tab-separated column. |
||
uniq |
uniq file |
Removes duplicate lines from file. |
|
uniq -c file |
Counts the number of occurrences of each line in file. |
||
split |
split -l 10000 file.txt |
Splits file.txt into smaller files with 10,000 lines each. |
|
wc |
wc -l file |
Counts the number of lines in file. |
|
wc -w file |
Counts the number of words in file. |
||
join |
join file1 file2 |
Joins lines of file1 and file2 on a common field. |
|
head |
head -n 100 filename |
Displays the first 100 lines of filename. |
|
tail |
tail -n +1000 filename |
Displays lines starting from line 1000 of filename. |
|
| Data Statistics and Analysis | xargs |
ls | xargs grep "pattern" |
|
tee |
command | tee file |
||
command | tee -a file |
|||
| Compression and Archiving | gzip |
gzip filename |
Compresses filename using the gzip algorithm. |
gzip -d filename.gz |
Decompresses filename.gz. |
||
tar |
tar -cvf archive.tar /path/to/directory |
Creates a tar archive without compression. | |
tar -zcvf archive.tar.gz /path/to/directory |
Creates a tar archive with gzip compression. | ||
tar -xf archive.tar -C /destination |
Extracts a tar archive to the specified destination. | ||
tar -xzf archive.tar.gz -C /destination |
Extracts a gzip-compressed tar archive to the specified destination. | ||
tar -cvf archive.tar /path --exclude=*log* --exclude=*data* |
Creates a tar archive while excluding files matching patterns. | ||
zip |
zip archive.zip file1 file2 |
Compresses file1 and file2 into archive.zip. |
|
zip -r archive.zip directory/ |
Recursively compresses directory into archive.zip. |
||
| Data Flow and Process Management | ps |
ps aux --sort=-%mem |
Lists processes sorted by memory usage. |
ps -ef |
Displays all running processes. | ||
ps -eaf |
Another variant to display all processes. | ||
top |
top |
Displays real-time system processes and resource usage. | |
kill |
kill -9 $pid |
Forcefully terminates a process with the specified PID. | |
pgrep |
pgrep process_name |
Searches for processes by name and returns their PIDs. | |
bg |
bg %job |
Resumes a suspended job in the background. | |
jobs |
jobs |
Lists active jobs in the current shell. | |
nohup |
nohup command > output.log 2>&1 & |
Runs command immune to hangups, redirecting output to output.log and running it in the background. |
|
| Network and File Transfer | wget |
wget <http://example.com/file.zip> |
Retrieves file.zip from the specified URL. |
wget -O output.txt <http://example.com/data> |
Downloads data from the specified URL and saves it as output.txt. |
||
scp |
scp file.txt user@remote:/path/ |
Securely copies file.txt to a remote host. |
|
scp -r /local/dir user@remote:/path/ |
Securely copies a directory recursively to a remote host. | ||
netstat |
netstat -tunpl \| grep [port] |
Lists listening ports and associated processes. | |
netstat -nap \| grep [pid] |
Shows network connections for a specific PID. | ||
nc (netcat) |
nc -zv host port |
Scans host on port to check if it's open. |
|
nc host port |
Connects to host on port for data transfer or communication. |
||
| System Information and Monitoring | df |
df -h |
Reports file system disk space usage in a human-readable format. |
df -T |
Shows the type of file system. | ||
du |
du -h --max-depth=1 |
Displays disk usage in a human-readable format, limited to one directory level. | |
du -sh test_dir |
Shows the total disk usage of test_dir. |
||
iostat |
iostat |
Reports CPU and I/O statistics for devices and partitions. | |
| File Search | find |
find . -name "*.log" |
Searches for all .log files in the current directory and subdirectories. |
find /path -type f -size +100M |
Finds files larger than 100MB in /path. |
||
which |
which gcc |
Locates the executable path for gcc. |
|
| Permission Management | chmod |
chmod u+r file |
Adds read permission for the user on file. |
chmod o-r file |
Removes read permission for others on file. |
||
chmod 755 script.sh |
Sets permissions to rwxr-xr-x for script.sh. |
||
chown |
chown user:group file |
Changes ownership of file to user and group. |
|
chown -R user:group directory/ |
Recursively changes ownership of directory and its contents to user and group. |
||
ls -l |
ls -l |
Lists directory contents in long format, showing permissions and ownership. | |
| Other Tools | env |
env |
Displays the current environment variables. |
env VAR=value command |
Sets an environment variable VAR to value for the duration of command. |
||
date |
date |
Displays the current date and time. | |
date +"%Y-%m-%d" |
Outputs the date in YYYY-MM-DD format. | ||
watch |
watch -n 1 ls |
Executes ls every second, updating the display. |
|
alias |
alias ll='ls -al' |
Creates an alias ll for ls -al. |
|
alias gs='git status' |
Creates an alias gs for git status. |
||
| Advanced Tools | jq |
jq '.' file.json |
Parses and formats JSON data from file.json. |
jq '.key' file.json |
Extracts the value of key from file.json. |
||
| Network Configuration and Management | netplan |
netplan apply |
Applies the network configuration defined in Netplan YAML files. |
ip |
ip addr add 10.240.224.117/24 dev ens9f0 |
Adds an IP address to the network interface ens9f0. |
|
ip route add default via 10.240.224.1 |
Adds a default gateway route via 10.240.224.1. |
||
ip a sh dev ens1f0 |
Shows the address information for the device ens1f0. |
||
ip l s ens1f0 up |
Sets the link state of ens1f0 to up. |
||
ifconfig |
ifconfig up ens9f0 |
Brings up the network interface ens9f0. |
|
ifconfig ens9f0 |
Displays the configuration of the network interface ens9f0. |
||
| Networking Utilities | nslookup |
nslookup child-prc.intel.com |
Queries DNS to obtain domain name information for child-prc.intel.com. |
Delve into prometheus
1. Introduction to Time Series Data
TL;DR
Time series data is a sequence of data points collected or recorded at specific time intervals, typically used to track changes or trends over time.
Data Schema
- Structure:
identifier -> (t0, v0), (t1, v1), (t2, v2), ...
Data in Prometheus
- Format:
<metric_name>{<label_name>=<label_value>, ...}
Example of a typical set of series identifiers (data model):
1 |
|
Components:
- Key: Series
- Metric Name:
__name__ Labels:
1
{"pod": "example-pod", "job": "example-job", "path": "/api/v1/resource", "status": "200", "method": "GET"}
- Timestamp: Recorded time of the sample
- Metric Name:
- Value: Sample value
How to Query:
- Example Queries:
__name__="http_requests_total"- Selects all series belonging to thehttp_requests_totalmetricmethod="PUT|POST"- Selects all series where the method is either PUT or POST
HA v.s. Reliability
High Availability (HA) and Reliability are two important concepts in system design, but they address different aspects of system performance and robustness. Below, I'll provide code examples and explanations to illustrate the differences between HA and Reliability.
High Availability (HA)
High Availability focuses on ensuring that a system is operational and accessible for as much time as possible. This often involves redundancy and failover mechanisms to minimize downtime.
Example: High Availability with Load Balancer and Multiple Instances
1 |
|
why the function of controller in kubernete operator is called "reconcile"
In Kubernetes, the term "reconcile" is used to describe the process by which an operator controller ensures that the current state of a resource matches the desired state specified by the user.
The name "reconcile" is derived from the concept of reconciliation, which means to make consistent or congruent.
- Desired State vs. Current State:
- Kubernetes operates on a declarative model where users specify the desired state of the system using YAML or JSON manifests.
- The actual state of the system is the current state of the resources as observed in the cluster.
- Reconciliation Loop:
- The core responsibility of a Kubernetes controller (including operators) is to continuously monitor the current state of resources and compare it with the desired state.
- If there is a discrepancy between the desired state and the current state, the controller takes actions to bring the current state in line with the desired state. This process is known as reconciliation.
- Reconcile Function:
- The "reconcile" function is the heart of this process. It is called whenever there is a change in the resource or periodically to ensure the desired state is maintained.
- The function typically involves reading the current state of the resource, comparing it with the desired state, and then performing the necessary operations (such as creating, updating, or deleting resources) to reconcile the two states.
- Idempotency:
- The reconcile function is designed to be idempotent, meaning that running it multiple times with the same input should produce the same result. This ensures that the system remains stable and consistent even if the function is triggered multiple times.
- Event-Driven:
- The reconciliation process is often event-driven. When a resource changes (e.g., a new pod is created, or a deployment is updated), an event is generated, and the reconcile function is triggered to handle the change.
In summary, the name "reconcile" aptly describes the function's role in ensuring that the actual state of the system matches the desired state as defined by the user. It reflects the continuous and iterative nature of the process, where the controller works to "reconcile" any differences between the two states.
graph TD
A[User Request] -->|kubectl| B[API Server]
B --> C[etcd]
B --> D[Controller Manager]
D -->|Reconcile Loop| E[Custom Controller]
E -->|Check Desired State| F[etcd]
E -->|Check Current State| G[API Server]
E -->|Update Resources| H[Scheduler]
H --> I[Nodes]
I -->|Run Pods| J[Actual State]
J -->|Report Status| G
G -->|Update Status| F
F -->|Store State| C
Kafka cluster networking
graph TB
subgraph "Kafka Cluster"
Broker1["Broker 1"]
Broker2["Broker 2"]
Broker3["Broker 3"]
end
subgraph "Topic: my-topic (3 Partitions)"
P0["Partition 0"]
P1["Partition 1"]
P2["Partition 2"]
end
P0 --> LeaderP0["Leader (Broker 1)"]
P0 --> FollowerP0_B2["Follower (Broker 2)"]
P0 --> FollowerP0_B3["Follower (Broker 3)"]
P1 --> LeaderP1["Leader (Broker 2)"]
P1 --> FollowerP1_B3["Follower (Broker 3)"]
P1 --> FollowerP1_B1["Follower (Broker 1)"]
P2 --> LeaderP2["Leader (Broker 3)"]
P2 --> FollowerP2_B1["Follower (Broker 1)"]
P2 --> FollowerP2_B2["Follower (Broker 2)"]
Producer["Producer"] -->|Write to Leader| LeaderP0
Producer -->|Write to Leader| LeaderP1
Producer -->|Write to Leader| LeaderP2
ConsumerGroup1["Consumer Group 1"] -->|Consume from Partition 0| LeaderP0
ConsumerGroup1 -->|Consume from Partition 1| LeaderP1
ConsumerGroup1 -->|Consume from Partition 2| LeaderP2
ConsumerGroup2["Consumer Group 2"] -->|Consume from Partition 0| LeaderP0
ConsumerGroup2 -->|Consume from Partition 1| LeaderP1
ConsumerGroup2 -->|Consume from Partition 2| LeaderP2
Zookeeper["ZooKeeper / KRaft"] -->|Manage Metadata & Leader Election| Broker1
Zookeeper --> Broker2
Zookeeper --> Broker3
Outside network request access the k8s operator
how does the outside (cluster) network request access the k8s operator and final the operator handle the process? answer the process in low level, suck as tcp/ip, k8s service mechanism, CRD, operator reconcile, manager and controller in operator, etc
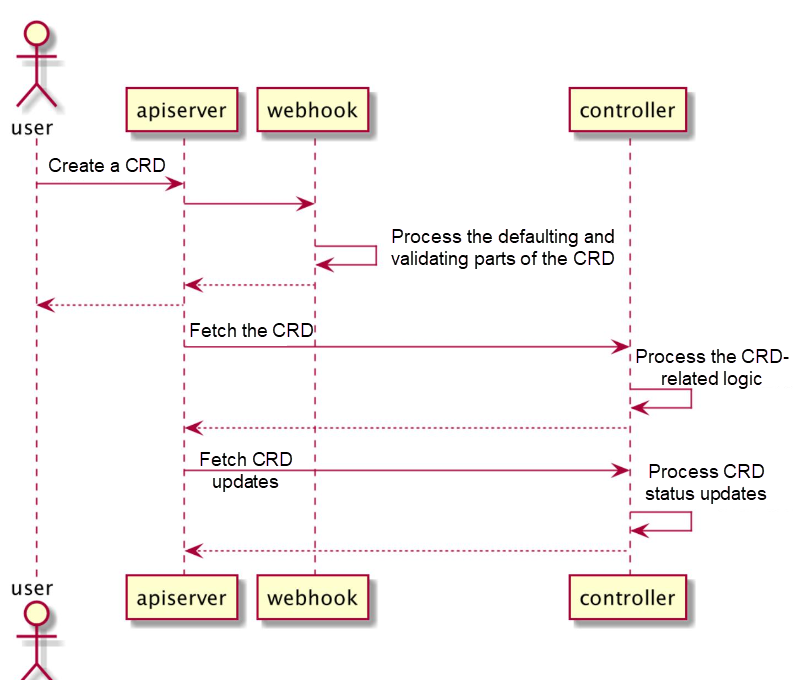
flowchart TD
A[External Request] --> B[DNS Resolution]
B --> C[TCP/IP Connection Established]
C --> D[Load Balancer / Ingress Controller]
D --> E[Kubernetes Service]
E --> F[Forward Request to Operator Pod]
subgraph Operator Pod Components
F --> G[Operator Manager]
G --> H[Controller Watches CRD Changes]
H --> I[Reconciliation Loop]
I --> J[Current State Assessment]
J --> K[Compute Difference]
K --> L[Execute Changes to Reach Desired State]
end
I --> Z[Sync State with CRD]
L --> Z
To understand how an external network request reaches a Kubernetes (k8s) operator and how the operator processes it, we need to dissect the journey step by step, focusing on the underlying mechanisms like TCP/IP, Kubernetes services, Custom Resource Definitions (CRDs), and the internal workings of an operator, including the reconcile loop, managers, and controllers.
Loki Storage Optimization
1. Use Cold/Hot Storage Separation
Approach:
- Hot Data (logs from the last few days or weeks): Stored in fast storage (like SSDs) for frequent access.
- Cold Data (historical logs): Stored in object storage (like MinIO, S3) for long-term archiving and infrequent access.
Example Loki Configuration:
1 | storage_config: |
Optimization Effect:
- Reduces local storage pressure by moving historical logs to object storage.
- Improves query performance: prioritizes hot data queries, with slightly higher latency for cold data queries but at lower costs.
Monitoring the Loki Logging System
Monitoring the Loki Logging System
In a high-concurrency environment where Loki handles intensive log processing and storage, monitoring metrics are essential for ensuring system stability, performance optimization, and dynamically adjusting configurations (such as replicas and sharding). Here are the main Loki component metrics you can monitor to dynamically adjust system settings as needed:
1. Loki Ingester Metrics
loki_ingester_memory_usage_bytes:Monitors memory usage for each Ingester instance. If memory usage remains close to system limits, consider increasing the number of Ingester replicas to distribute the load.
- Purpose: Dynamically scale up or down the number of Ingester replicas based on memory usage.
loki_ingester_wal_fsync_duration_seconds:Monitors the time each Ingester instance takes to write WAL (Write-Ahead Log) data to disk. High write durations may indicate that write throughput is nearing its limit; consider expanding sharding or increasing storage bandwidth.
- Purpose: Use WAL write latency to determine if scaling or storage optimization is needed.
loki_ingester_chunk_store_writes_totalandloki_ingester_chunk_store_reads_total:Monitors the total number of chunk reads and writes. If write volume spikes, consider expanding the storage layer by adding more storage nodes to improve write performance.
- Purpose: Assess whether to increase storage capacity or optimize storage performance.
2. Loki Distributor Metrics
loki_distributor_received_bytes_total:Monitors the total volume of log data received by the Distributor. If data volume significantly increases, consider adjusting the sharding strategy or adding more Distributor instances.
- Purpose: Adjust sharding strategy based on log traffic and dynamically manage sharding to distribute log data.
loki_distributor_ring_members:Monitors the number of Ingesters actively handling log traffic in Loki's sharding model. If the number of active members is lower than expected (e.g., some Ingester nodes have crashed), consider increasing the number of Ingester replicas.
- Purpose: Scale up or down the number of Ingester replicas based on the number of active Ingesters.
loki_distributor_accepted_requests_totalandloki_distributor_rejected_requests_total:Monitors the number of accepted and rejected requests. Rejected requests may indicate that the system is overloaded, and additional capacity may be necessary.
- Purpose: Adjust replicas and load distribution based on the count of rejected requests and system load.
3. Loki Querier Metrics
loki_querier_request_duration_seconds:Monitors query response times. If query response times increase, it may indicate high query load, in which case you may need to scale up the number of Querier instances.
- Purpose: Dynamically add Querier instances to handle more query requests and reduce response times.
loki_querier_requests_total:Monitors the total number of query requests. If the query volume becomes too high, it could slow down the system, so consider increasing the number of Querier replicas.
- Purpose: Scale Querier instances up or down based on query volume to improve response speed.
4. Storage Metrics
loki_chunk_store_writes_totalandloki_chunk_store_read_duration_seconds: Monitors chunk data read/write time and frequency in storage. High write frequency or increased read time may indicate a storage performance bottleneck, necessitating either additional storage capacity or optimized storage strategies.- Purpose: Adjust storage configuration and add storage nodes to minimize storage bottlenecks affecting query or write performance.
5. System-Level Resource Monitoring
CPU and Memory Usage: Using Prometheus or Kubernetes' native monitoring tools (like HPA or VPA), monitor CPU and memory usage for Loki components (e.g., Ingester, Distributor, Querier). If resource usage for any component approaches its limits, consider horizontally scaling the number of replicas for that component.
- Purpose: Dynamically adjust replicas based on CPU and memory usage.
6. High Availability Monitoring
loki_ring_members: Monitors the number of nodes in Loki's sharding ring, ensuring all nodes in the cluster are active. If node count decreases, consider rebalancing the shards or adding more instances to compensate for lost nodes.- Purpose: Dynamically adjust high-availability configurations based on ring member count.
Dynamic Adjustment Mechanisms:
1. Replica-Based Dynamic Scaling:
When metrics like
loki_ingester_memory_usage_bytesorloki_distributor_received_bytes_totalindicate high load, you can dynamically increasereplicasby usingkubectl scaleor HPA (Horizontal Pod Autoscaler) to adjust instance numbers based on real-time load.Example: Use HPA to automatically scale Promtail, Ingester, or Querier instances:
1
kubectl autoscale statefulset loki-ingester --min=3 --max=10 --cpu-percent=80
2. Sharding-Based Dynamic Scaling:
When metrics like
loki_distributor_received_bytes_totalorloki_ingester_chunk_store_writes_totalshow a surge in log traffic, adjust theshard_by_all_labelsconfiguration or use theshardingparameter in Loki’s configuration to dynamically increase the number of log shards.Example: Increase
shardcount for Distributors and Ingesters to distribute more log data across multiple Ingester nodes.
These metrics can be easily collected with Prometheus and displayed in Grafana. Combined with Loki's configuration adjustments, they enable real-time dynamic configuration optimization to ensure system performance and stability in high-concurrency environments.
Loki System Scalability
graph TD
subgraph Loki Stack
A[Client] -->|Push Logs| B[Distributor]
B -->|Distribute Logs| C[Ingester]
C -->|Store Logs| D[Chunk Store]
E[Querier] -->|Fetch Logs| D
F[Query Frontend] -->|Distribute Queries| E
G[Client] -->|Query Logs| F
end
subgraph External Systems
H[Promtail] -->|Send Logs| A
I[Grafana] -->|Visualize Logs| G
end
Components Description
- Distributor: Receives log data from clients and distributes it to the ingesters.
- Ingester: Processes and stores log data temporarily before it is flushed to the chunk store.
- Chunk Store: A long-term storage solution for log data, such as an object store (e.g., S3, GCS).
- Querier: Fetches log data from the chunk store to respond to user queries.
- Query Frontend: Distributes incoming queries to multiple queriers for load balancing and parallel processing.
- Promtail: A log collection agent that sends logs to the Loki distributor.
Interaction Flow
- Log Ingestion:
- Logs are sent from the Client to the Distributor.
- The Distributor distributes the logs to multiple Ingesters.
- Ingesters process and temporarily store the logs before flushing them to the Chunk Store.
- Log Storage:
- Ingesters periodically flush processed logs to the Chunk Store for long-term storage.
- Log Querying:
- Clients (e.g., Grafana) send queries to the Query Frontend.
- The Query Frontend distributes the queries to multiple Queriers.
- Queriers fetch the required log data from the Chunk Store and return it to the Client.
Optimization Actions for High-Concurrency Log Processing and Storage Scalability
graph TD
%% Clients and Log Collection
Client[Clients / Applications] -->|Send Logs| Promtail[Promtail]
%% Ingestion Pipeline
Promtail -->|Push Logs| Distributor[Distributor Cluster]
Distributor -->|Distribute to| Ingesters[Ingester Cluster]
%% Storage Layers
Ingesters -->|Write to| Storage["Object Storage
(S3, GCS, etc.)"]
Ingesters -->|Maintain Temporary Data| Cache[In-Memory Cache]
%% Query Pipeline
Querier[Querier Cluster] -->|Fetch from Storage| Storage
Querier -->|Retrieve from Cache| Cache
Querier -->|Access Index| Index[Index Gateway]
%% Compaction and Maintenance
Compactor[Compactor] -->|Compact Data| Storage
%% Alerting and Visualization
Ruler[Ruler] -->|Fetch Rules| Storage
Ruler -->|Evaluate Alerts| Querier
Grafana[Grafana] -->|Visualize Logs| Querier
Grafana -->|Manage Alerts| Ruler
%% Additional Interactions
Ingesters -->|Send Metrics| Metrics[Metrics & Monitoring]
Querier -->|Send Metrics| Metrics
Distributor -->|Send Metrics| Metrics
Promtail -->|Send Metrics| Metrics
Ruler -->|Send Metrics| Metrics
Compactor -->|Send Metrics| Metrics
Grafana -->|Display Metrics| Metrics
1. Horizontal Scaling of Log Collection: Promtail
- Action: Increase the number of Promtail instances to handle the load of log collection in a high-concurrency environment. Promtail is Loki's log collection agent, responsible for gathering logs from various nodes.
- Implementation:
- In a Kubernetes cluster, configure Promtail as a DaemonSet to ensure an instance runs on each node, enabling automatic scaling across all nodes for comprehensive log collection.
- When workload increases in the cluster, dynamically adjust the number of Promtail instances to prevent log collection from becoming a bottleneck. Use Kubernetes Horizontal Pod Autoscaling (HPA) to scale Promtail instances up or down based on log collection load.
- Key Technology: Utilize Kubernetes load balancing to evenly distribute logs from different nodes to Promtail instances, in combination with HPA for dynamic scaling.
2. Sharding and Partitioning Strategy for Loki Storage Layer
- Action: To address storage bottlenecks, implement sharding and partitioning strategies at the Loki storage layer, distributing logs across multiple storage nodes to enhance write throughput.
- Implementation:
- Configure the storage layer (e.g., using S3 or MinIO) in Loki for distributed storage, using sharding and partitioning to spread logs across various storage nodes. Each node handles only part of the data, reducing write pressure on individual nodes.
- Specify multiple storage targets in Loki's configuration, allowing horizontal scaling across multiple physical or virtual storage nodes to improve fault tolerance and storage performance.
3. Parallel Processing: Ingester
- Action: The Ingester component in Loki is responsible for receiving and processing log data. In high-concurrency environments, increase the number of Ingester instances to enable parallel log processing.
- Implementation:
- Increase the number of Ingester instances, with each instance handling a portion of the log data. By introducing sharding, each Ingester processes only part of the log stream, avoiding overload on individual instances.
- Deploy Loki using Kubernetes StatefulSets and leverage Loki's replication and consistency model to ensure log data processing continuity even if some Ingester nodes fail.
4. Monitoring and Dynamic Adjustment: Prometheus Monitoring and Scaling Strategy
- Action: To ensure dynamic adjustment capabilities, design a real-time monitoring and auto-scaling strategy based on Prometheus.
- Implementation:
- Use Prometheus to monitor load metrics for each component of the Loki Stack (e.g., Promtail, Ingester, Querier), including log collection throughput and storage latency.
- Based on monitored metrics, dynamically adjust the number of Promtail and Ingester instances, scaling up during peak periods and scaling down during lower loads to save costs.
- Monitoring metrics